Building Wattpad Downloader
Reverse-engineering Wattpad's API to download books at scale with a SvelteKit + FastAPI Hybrid-Stack.
Wattpad Downloader (available here) allows one to read Wattpad books their way. The native app is constrained and locked down, and personally, I like reading on my Kindle!
I manage my books using Calibre and read them using KOReader. Highlights and Notes are synced to the knowledgebase via a fork of obsidian-koreader-sync.
WattpadDownloader was something I made for myself and coincidentally made open-source. It blew up, so I've rewritten the app to be more user-friendly :)
In this blog-post, I'll talk about how I:
- Reverse engineered Wattpad's API
- Programmatically generated EPUBs with aerkalov/ebooklib
- Put it all together with a Tailwind Frontend & a Python API!
- Built the Frontend and served it via the API
- Implemented Caching and Ratelimits after the app's newfound fame
Reverse Engineering Wattpad's API
Wattpad doesn't have a documented API for developers, leaving us to reverse engineer the APIs powering the frontend.
My friend, Ruthenic, developed wattpad-rs. I wanted something for Python, I'll make a subsequent post on wattpad-py's development. For now, let's focus on downloading books!
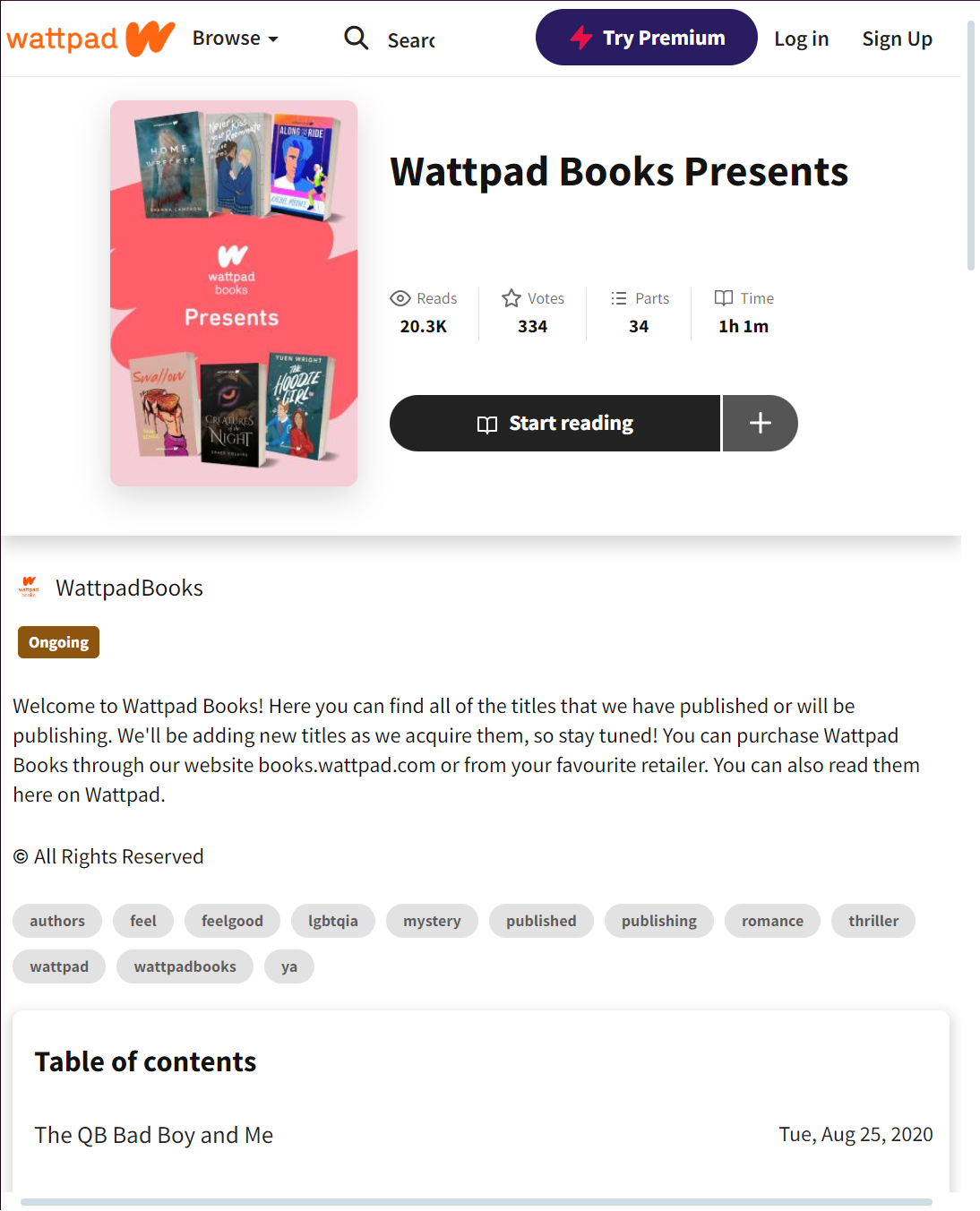
Let's try downloading the above story!
First, the URL in the browser: https://www.wattpad.com/story/237369078-wattpad-books-presents. This contains the Story ID, which is the first group of numbers we find - 237369078.
With this ID in hand, let's take a look at what's going on behind-the-scenes. To our luck, Wattpad doesn't render their pages on the server, allowing them to be hydrated with data on the client-side. This means there's an API we can hook into to fetch data.
With some quick analysis, we find that the following API is used: https://www.wattpad.com/api/v3/stories/237369078?fields=.... A Story Book consists of Chapters, a Wattpad Book is made up of 'Parts'.
That's what we're interested in, using the API, let's fetch the book's Title, Cover, and Parts. That gives us the following URL: https://www.wattpad.com/api/v3/stories/237369078?fields=title,parts(id,title,url),cover (click it!).
{
"title": "Wattpad Books Presents",
"cover": "https://img.wattpad.com/cover/237369078-256-k815402.jpg",
"parts": [
{
"id": 939051741,
"title": "The QB Bad Boy and Me",
"url": "https://www.wattpad.com/939051741-wattpad-books-presents-the-qb-bad-boy-and-me"
},
...
]
}The API's response looks like the above, but we still don't have the actual text of each chapter. All's not for naught though, there's another API which returns a chapter's text given its ID.
To recap, the first API call gives us a list of Chapter IDs, the second one gives us text for each chapter.
Upon further analysis, we can figure out that content API is here: https://www.wattpad.com/apiv2/?m=storytext&id=939051741&page=1. This link gives us the chapter's content as HTML, which is a blessing in disguise. EPUBs are composed of HTML files, so this saves us a great deal of work - We can directly parse this API's response to produce books which look just as they would on the app! (Ie, custom styling isn't lost.)
These two APIs form the backbone of our backend.
for part in get_parts():
add_to_epub(get_part_content(part.id))
Is all the backend is.
Included Metadata: Author Information, Tags, Descriptions, Publishing & Modification Dates, Age Ratings, and Language Information
EPUB Generation
There were a few roadblocks here, but time and documentation fixes everything.
After importing epub from the ebooklib module, we can generate an EPUB Chapter for each part in the story.
chapter = epub.EpubHtml(
title=title,
file_name=f"{title}.xhtml",
lang=lang,
)
chapter.set_content(f"<h1>{title}</h1>" + content)We create a Book object via book = epub.EpubBook() and add these chapters using the .add_item() method.
There's not much here, the documentation is plentiful and the examples are useful.
Metadata can be added through book.add_metadata("DC", "description", data["description"]).
The Frontend
The original frontend didn't offer much past a shiny download button, here's a picture

The reddit thread got a few common questions, and it made sense to include a small manual on the Website.
Alongside this, 80% of my users use mobile devices to interact with the site. That should be fine in theory, but I didn't write the original frontend with the expectation of it being used on a mobile device (or by anyone at all lol!). To improve UX, I'd have to make my website responsive.
Taking both into account, I speedwrote a new frontend for the site.
Desktop:

Mobile:
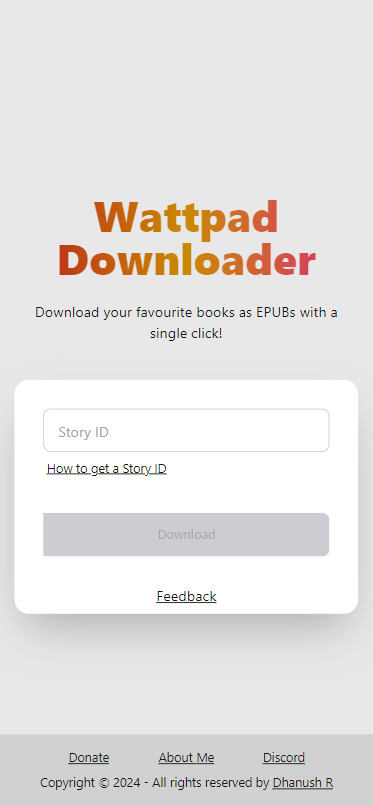
I carried over the signature gradient text! The current version is mobile-friendly and should lead to a better UX. I'll be listening for feedback on the Discord server! (And FeedbackFish, Thanks SSouper).
Building
Right now, our stack consists of a FastAPI Backend and a SPA on SvelteKit. I've written a Dockerfile for such projects, and this code in the API mounts the built website - The benefit of this approach, albeit solely for static websites, is that API Routes can be relative. The frontend can reference /download - this works as the frontend is served _through_ the API. Big timesaver.
Place app.mount("/", StaticFiles(directory=BUILD_PATH), "static") after all your routes have been defined. This prevents the static files from overwriting any API Routes.
@app.get("/")
def home():
return FileResponse(BUILD_PATH / "index.html")
With BUILD_PATH = pathlib.Path(__path__).parent / "build" pointing to the built frontend.
That's all for building!
Caching
The site is behind CloudFlare, but the caching I'm talking about is related to Wattpad's API. The goal is to make the least amount of requests possible - I don't want to get blocked, nor do I want the server to get ratelimited.
To do this, we'll use requests-cache/aiohttp-client-cache in the following way:
from aiohttp_client_cache import CachedSession, FileBackend
cache = FileBackend(
use_temp=True,
expire_after=...,
)
async with CachedSession(headers=headers, cache=cache) as session:
async with session.get() as response:
...
The cache's CachedSession aims to be a drop-in replacement for aiohttp.ClientSession, implementing caching was a breeze.
Ratelimits
Wattpad's Ratelimits aren't too strict, due to the lack of documentation, I don't have a precise number on how many requests is too many.
When a request fails, the backend requeues the request with a short delay. If it goes through, all's well and good. If not, the download is cancelled.
We're using a Backoff-and-retry strategy to handle Wattpad's Ratelimits.
That's all! The most interesting part about this project was seeing the surprising amount of demand for it, talking to users, and reverse-engineering the API.

Visit WattpadDownloader at wpd.rambhat.la!
Thanks for reading
Om
Deployment Data
{
"LiveURL": "https://wpd.rambhat.la",
"Repository": "https://github.com/TheOnlyWayUp/WattpadDownloader"
}